One of main advantages of openHAB is its flexible provider mechanism which allow to use of various sources of configurations.
The very core concept of a Thing is covered by ThingProvider, which have two primary implementations.
This article is intended to dive a bit deeper into how openHAB parses its *.things files and how they get processed internally.
Finally, we will bring a completely new implementation of such parser based on ANTLRv4 library.
Introduction
The core of openHAB embeds several important libraries.
One of them is Xtext which provides very flexible Domain Specific Language (DSL) toolkit.
This toolkit is used to parse not only *.things files.
It is used also for *.items and *.rules (although with a bit deeper use of Xtext).
Once things files are parsed, they form intermediate model which is based on Eclipse Modeling Framework (EMF).
The EMF provides some generic methods to work with… well various sorts of models.
Then Xtend is used once again, this time to generate GenericThingProvider class.
This class transforms EMF model into openHAB core model - free of EMF dependencies.
Does it sound complex? A bit. Can we make it simpler? Of course.
There are several troubles inherited through use of Xtext and EMF:
- The Xtext is based on fairly old ANTLR 3 version.
- The grammar syntax is intermediate - it is used to generate target ANTLR schema.
- There is a ANTLR lab which allows to test grammar online, by browser, but only for ANTLR 4.
- It depends on Eclipse Modeling Framework, which has its own weight.
- Generation of parser from Xtext requires use of fairly complex toolchain.
- There is very few people who can maintain Xtext / EMF stuff outside of Eclipse Foundation.
Making friendship with ANTLR v4
The ANTLR is a shortcut for ANother Tool for Language Recognition. ANTLR itself is a parser generator first developed by Terance Parr. ANTLR consist also a runtime library which is needed by generated parser. The core difference between Xtend and ANLTR is its role. While Xtend is toolkit, ANTLR is just a tool. Using second one requires more effort on our end, leaving us with some hard troubles to be solved.
However, by looking at standard thing definition used by openHAB DSL, we can see it as rather basic. Compared to rule DSL, its actually trivial, as it do no pose to be a fully fledged programming language.
The Thing DSL allows us to define:
- Things
- Bridges
- Thing and Bridge configuration (key value paris within square brackets)
- Channels within Things/Bridges
- Channel configuration (again key value paris within square brackets)
- Things within bridges
The only one hard part, at first look is nesting of Things within Bridges or Bridges within Bridges, due to how it impacts ID construction. The ANTLR grammar syntax itself is rather simple, difficulty is really distinguishing the lexer and parser rules. Both are evaluated at different stage of parsing process and have serious impact to how parser will behave. Sometimes, improperly defined lexer rule, may not ever match.
Deeper look at thing definition
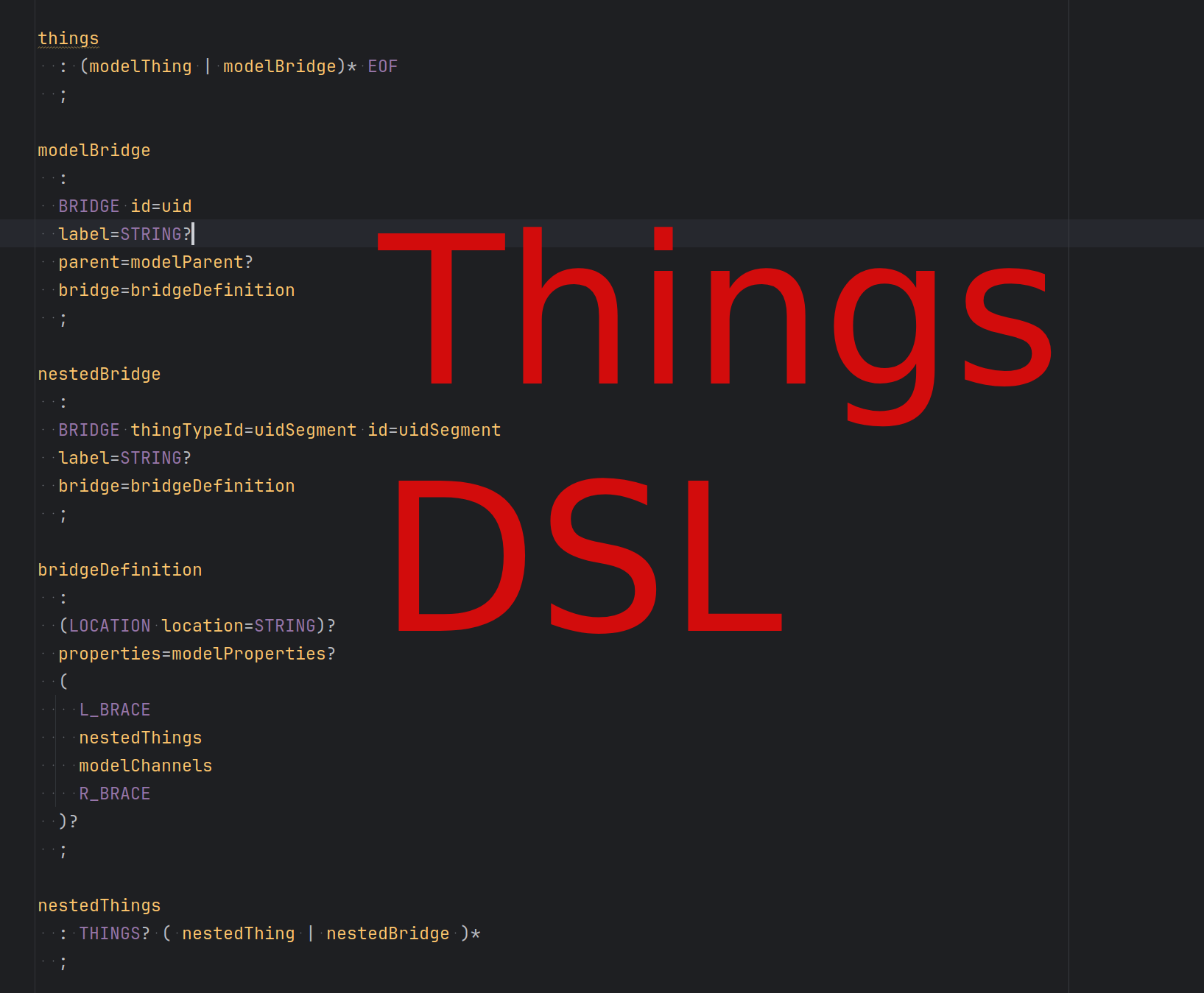
In the actual Things grammar, parsing starts from the things rule which accepts a sequence of modelThing and modelBridge elements until EOF.
Top-level and nested declarations are split on purpose: modelThing and modelBridge handle full UIDs.
They may contain nestedThing and nestedBridge, which handle shorter forms used inside bridge blocks.
Structure is then delegated to thingDefinition and bridgeDefinition, which cover optional location markers.
Below you can find few key parts of grammar, which follow above hierarchy. Note that there are some contants (such as L_BRACE, R_BRACE or STRING). These are lexer rules which uniquely identify a pattern matching criteria.
// subset of parser rules
things : (modelThing | modelBridge)* EOF;
modelBridge : BRIDGE id=uid label=STRING? parent=modelParent? bridge=bridgeDefinition;
bridgeDefinition : (LOCATION location=STRING)? properties=modelProperties? ( L_BRACE nestedThings modelChannels R_BRACE )?;
nestedThings : THINGS? ( nestedThing | nestedBridge )*;
modelThing : THING id=uid label=STRING? parent=modelParent? thing=thingDefinition;
nestedThing : THING thingTypeId=uidSegment id=uidSegment label=STRING? thing=thingDefinition;
thingDefinition : (LOCATION location=STRING)? properties=modelProperties? ( L_BRACE modelChannels R_BRACE )?;
modelChannels: CHANNELS? modelChannel*;
modelChannel : (channelDeclaration | channelReference) ':' id=channelId (label=STRING)? properties=modelProperties?;
channelDeclaration : (channelKind=CHANNEL_KIND)? itemType=modelItemType;
channelReference : TYPE channelType=uidSegment;
modelItemType : standardItemType | dimensionalItemType | dynamicItemType;
modelProperties: L_BRACKET properties=modelProperty? (',' properties=modelProperty)* R_BRACKET;
modelProperty : key=ID '=' value=valueType (',' value=valueType)*;
valueType : STRING | NUMBER | BOOLEAN;
Bracketed property lists contain bodies, with thing configuration options.
Inside thing bodies we can find modelChannels and modelChannel which describe both declared channels and typed channel references.
Property parsing which describes configuration options (both for thing and channel) is a sequence of key=value pairs.
What is unique in this attempt is that modelItemType, which is part of channel declaration is not fixed to only predefined types.
As you know openHAB supports Dimmer, Switch, Number, Contact and few other item types.
But not more than that.
Our parser accepts standard item types such Switch or Number (also Number:<dimension>), but parser permits also a plain ID values.
This gives runtime a chance to conduct dynamic lookup of registered item types at runtime.
Practical use
Based on full Thing4.g4 ANTLR grammar we can create a complete parser.
Since we can read files, we can also write them, cause that part is much easier.
The thing4 repository linked above exposes high level Parser and Writer interfaces.
These interfaces are fairly generic, so they work with any input and output, so not only DLS, but for example YAML or XML.
Build time validation
Since we have a standalone parser with limited set of dependencies we can use it during build time.
The thing4-maven-plugin, which is based on what is described in this article provides three goals:
parse-descriptorsreadsOH-INF/**/*.xmldescriptor files.process-descriptorsrenders descriptor data through templates.parse-writeparses source files and can optionally write them in another format.
This is enough for several practical tasks:
- verify
*.thingsfiles during build - convert
*.thingsdefinitions to other format i.e YAML - generate AsciiDoc from binding descriptors
- check input with different parser implementations
Example: validate thing files
The simplest case is syntax validation of example files:
<plugin>
<groupId>org.thing4.tools</groupId>
<artifactId>thing4-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>parse-write</goal>
</goals>
<configuration>
<includes>
<include>docs/examples/**/*.things</include>
</includes>
<parser>thing4</parser>
<type>org.openhab.core.thing.Thing</type>
</configuration>
</execution>
</executions>
</plugin>
Here the parser reads thing definitions and checks whether they can be mapped to org.openhab.core.thing.Thing.
No output writer is needed.
Example: convert thing files to YAML
The same goal can write parsed definitions to another format:
<plugin>
<groupId>org.thing4.tools</groupId>
<artifactId>thing4-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>parse-write</goal>
</goals>
<configuration>
<includes>
<include>*.things</include>
</includes>
<parser>openhab</parser>
<writer>yaml</writer>
<type>org.openhab.core.thing.Thing</type>
</configuration>
</execution>
</executions>
</plugin>
This configuration reads *.things files and emits matching YAML files.
The writer identifier becomes the output extension (in this case yaml).
Example: descriptor processing
The parser tooling is also useful next to binding descriptors:
<plugin>
<groupId>org.thing4.tools</groupId>
<artifactId>thing4-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>parse-descriptors</goal>
<goal>process-descriptors</goal>
</goals>
<configuration>
<outputExtension>adoc</outputExtension>
</configuration>
</execution>
</executions>
</plugin>
This configuration by default read project resources from OH-INF/thing/*.xml and OH-INF/config/*.xml.
Process descriptors goal is used to generate documentation files based on XML descriptors.
Minimum project example
The examples below show the kinds of files handled by this tooling.
They include a *.things source, a nested bridge example, YAML output and descriptor XML.
config-descriptions.xml
config-descriptions.xml
| |
demo.things
demo.things
| |
demo.yaml
demo.yaml
| |
nested-bridge.things
nested-bridge.things
| |
thing-types.xml
thing-types.xml
| |
Final remarks
Exchange of a DSL parser is not entirely trival. There are few implementation aspects, which may be hidden in how parsed data is processed and arranged. For example a slight modification in how property list is retained in memory (hash map to linked hash map) may impact a lot of places. Simply because all these places were tested against earlier implementation.
What we gained is something which support regular engineering work:
- build-time validation
- format conversion
- descriptor-driven documentation
- reuse of code across tooling/runtime
New parser is much smaller, with less abstractions. This makes it easier to test, easier to embed and easier to maintain.
All this work allows us to remove Xtext and EMF dependencies from build. These two dependency groups are approximatelly 2-4 MB together, so its a significant amount. Obviously, these are still needed for other syntaxes, but lets keep it as a topic for another article.